[ad_1]
The unique convergence of three megatrends has taken artificial intelligence out of academia and into ubiquitous everyday applications: big data, cloud computing, and advanced algorithms. Today, AI has fundamentally changed the way we create software, integrating it into everyday digital experiences such as composing emails, searching the web, buying clothes, finding and listening to music, and building websites. However, the adoption of AI in global infrastructure systems in manufacturing, transportation, aviation, power generation, financial services, and other industries has been somewhat slower.
These industries have a lot of data, but often the data is:
- Not public domain.Example: Oil Exploration or Oil and Gas Environmental Impact Report
- Annotating requires a highly knowledgeable human being.Example: sensor data from gas turbines, pumps, compressors
- They are held in various forms in complex data stores and are not always cleansed.Example: aircraft maintenance log or manual
These very real challenges make it impossible to apply the same AI techniques that have revolutionized internet searching, bill reading, language translation, and conversation retention to professional domains as-is.
Industrial AI practitioners find that traditional supervised machine learning approaches and large-scale models from academia and research often fail in their fields of expertise, making big data operationalization very difficult for commercial enterprises. I’m starting to realize that As Chirag Dekate, Senior Director Analyst at Gartner, said in his 2019 article, “While launching a pilot is deceptively easy, deploying to production is notoriously difficult.”
Rather than relying on data scientists and software developers, the key to industry adoption is empowering subject matter experts (SMEs) who understand processes and data well. However, enabling small businesses such as aircraft engineers, power plant operators, financial analysts, and customs brokers to intuitively and rapidly define, build, and deploy their own purpose-built AI requires data discovery, tools, automation, and and new approaches to validation are required. of data science.
Proven techniques for operationalizing the most prevalent forms of big data in the enterprise include:
Create early warnings for unplanned asset downtime using normal behavior modeling of digital sensor data
Industrial operations often rely on critical high-value assets such as gas turbines. A single day of unplanned downtime or outage can cost power and utility companies up to $300,000 in lost revenue. The disruption to consumers could be even more severe. Due to their critical nature, these systems are typically overbuilt with redundancy and have comprehensive preventive maintenance programs. Ironically, this makes traditional supervised machine learning difficult. This is because failures are rare during the life of the system.
Normal-behavior modeling is a domain-agnostic, semi-supervised machine learning technique that can be used to rapidly model a system by representing it as a combination of process parameters. SME identifies timeframes of normal system operation in historical data, and AI begins to learn potential relationships between process parameters. An autoencoder is a type of neural network that is trained on historical data and stores potential relationships as a set of weights. Once an autoencoder is trained, it can be used to predict or regenerate input process parameters. When the predicted or regenerated value of a process parameter does not match the measured historical value, the normalized error is used as an “abnormality” or measure of anomaly.
Before this type of normal operating model can be put into production, it should be backtested against a historical record of actual outages and events in the system. If the selected process parameters are adequately representative of the behavior of the system, some or all of them will begin to trend into unusual ranges prior to shutdown. A normal behavioral model should predict this by increasing the level of anomalies. It can be used to create an early warning system for future outages, provided that the anomaly level is elevated sufficiently prior to continued outages.
In practice, hyperparameter optimization can be used to automatically train dozens or even hundreds of well behaved models. An objective function is created that measures both prediction accuracy and early warning length. This objective function allows you to programmatically evaluate and rank all model variants and deploy the best ones to production. An additional layer of tuning can be added to select appropriate dynamic thresholds for alerting based on anomaly levels and user preferences.
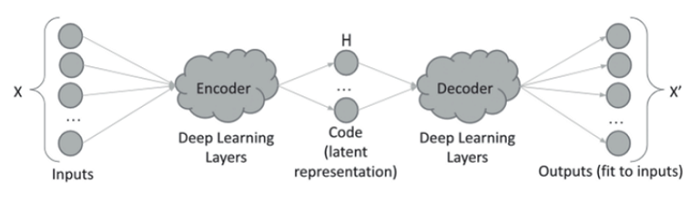
Normal behavior models have the following advantages over traditional modeling:
- Domain agnostic. This approach can be used as long as process variables are measured/recorded with reasonable frequency and accuracy.
- unsupervised learning. Preliminary efforts have been limited to variable selection and identification of nominal operating conditions, which her SME can usually perform.
Finding Patterns in Natural Language Records Using Ad Hoc Density-Based Clustering
Natural language records are very common in industrial environments, forming the basis of a wide range of processes such as product testing, application/security logging, equipment maintenance, logistics, and shipping. In practice, most records in an enterprise are semi-structured records, consisting of one or more columns of structured data (number, date, categorical) and one or more columns, usually created for human consumption. Features columns or natural language text. In enterprises, the need for semi-structured records is almost urgent. In an ideal world, all data collected about a process could be numbers, dates, and multiple-choice categorical elements. However, in practice, there are multiple reasons why natural language is introduced into the record.
- Not all process modalities are known at design time, and you end up knowing the “other” or all categories.
- Instructions and procedures are best expressed in natural language and are constantly improving over time.
- Troubleshooting, diagnostics, investigations, etc. typically generate previously unknown knowledge and require natural language.

Corporate operational records are often functional/brief, contain typos and colloquialisms, and commonly contain acronyms and jargon (e.g. ty-wrap = Tyvek wrap, ee = employee). This makes standard search and natural language modeling techniques somewhat inefficient. Moreover, there are potentially infinitely many ways to use natural language, so a blanket scheme for normalization cannot be advocated. for example. The above accidents can be categorized by their severity (minor injuries) or by the point of injury (hand injuries). The two categories are not mutually exclusive and should be considered separate categorization schemes. Without significant efforts by small businesses, most natural language records remain largely unanalysed and underutilized.
A practical approach to finding useful patterns in natural language records is ad-hoc clustering. To retrieve information, SMEs first use common search techniques on records. However, reading through hundreds of results is often tedious, and information can be missed by simply consuming the top “n” results. To avoid these pitfalls, AI applies density-based clustering to search results. Density-based approaches, such as DBSCAN and HDBSCAN, used for embedding sentences in records tend to cluster semantically similar languages while being less sensitive to spelling, conjugation, typos, and colloquialisms. A small business can easily read a few representative records in a cluster and fully understand them. Additionally, analyzing the top ‘n’ clusters typically reveals patterns of all the key information contained in the search results. These clusters can also be early candidates for classification schemes that can create a gradual categorical structure around the data. This technique has consistently shown high value in long-tail search problems when SME intent cannot be accurately and completely known in advance, but can be defined and applied over time.
Retrieving information or knowledge from documents using Discovery Loops
To make critical and time-sensitive decisions, analysts across all industries, government agencies, and military sectors are faced with an overwhelming amount of content to process. Executives expect analysts to accurately interpret reports, news, recommendations, and research to provide decision support for making confident and well-considered decisions. Searching for the right content through exploratory reading is cognitively taxing and causes decision fatigue. It explores esoteric concepts that are difficult to articulate in terms of Analysts generally agree that “they know it when they see it.”

Given the example narrative text from the news excerpt above:
The second example doesn’t actually use the word “outbreak”, but SMEs may readily assess it as a leading indicator of an outbreak. To address these difficult knowledge capture scenarios, SMEs first search for documents using one or more keywords that describe the ideas they want to find. Discovery Loop AI then selects the 25-50 most representative sentences from the results and, with simple point-and-click gestures, allows SMEs to classify the results into one or more meaningful categories. Alternatively, SME can specify substrings from sentences and extract them verbatim. AI trains her CNN classifier to learn categories assigned by SME. Sentences that are not bucketed are automatically assigned to the “uninteresting” category. A model trained in this way performs inference on every sentence in the original search results. Based on the inferred category predictions and their relative prediction confidences, the AI presents at least two of her sentence groups for her SME to review and/or revise. In the first group of 25-50 sentences. The AI only needs to train the model on 25-50 sentences and perform inference on the search results, so the loop typically takes only a few minutes. Similarly, each review group is only 25-50 sentences each, requiring only a few minutes of review by an SME. This rapid iteration is known as a discovery loop, allowing SMEs to quickly discover information rather than just reading and deciding on the gist without focusing on keywords. As the SME curates more labeled sentences, the AI retrains the classification or extraction model to improve accuracy and performs query expansion using the keywords extracted from the labeled sentences to improve the document set increase the coverage of At any time, the model can be run against all sentences in the document set to obtain a comprehensive subset of sentences that match the esoteric concepts defined by SME. This can be cited or referenced as evidence in analyst reports.
Both ad-hoc density-based clustering and Discovery Loop offer the following advantages over traditional supervised classification approaches:
- Reduces the burden of cumbersome and comprehensive labeling required upfront with traditional approaches
- Allow small businesses to create categories incrementally as they discover new information
- Allow small businesses to model only a useful subset of their data
A common denominator for all techniques is augmenting the SME’s knowledge and intuition with AI, allowing them to focus on high-value decisions. By avoiding the traditional supervised modeling approaches common in academia, these techniques focus on rapid utility by delivering just-in-time intelligence at the fingertips of SMEs.
About the author

Jaidev Amrite, Head of Product, Visual AI Advisor and DeepNLP, SparkCognition, said: Prior to SparkCognition, he led multiple product development initiatives in IIoT, data analytics, and embedded systems at National Instruments and Microsoft. He holds a master’s degree in electrical and computer engineering from Georgia Tech and is passionate about making technology accessible through human-centered design and social psychology.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1
[ad_2]
Source link
