[ad_1]
Especially in the last few years, real-world photo editing with non-trivial semantic adjustments has been a fascinating challenge in image processing. In particular, being able to control an image by solely a brief natural language text prompt would be a disruptive innovation in this field.
The current top methods for this task still present different shortcomings: firstly, they usually can only be used with images from a particular domain or artificially created images. Secondly, they present a limited set of edits, such as painting over the image, adding an object, or transferring style. Thirdly, they require auxiliary inputs in addition to the input image, such as image masks indicating the desired edit location.
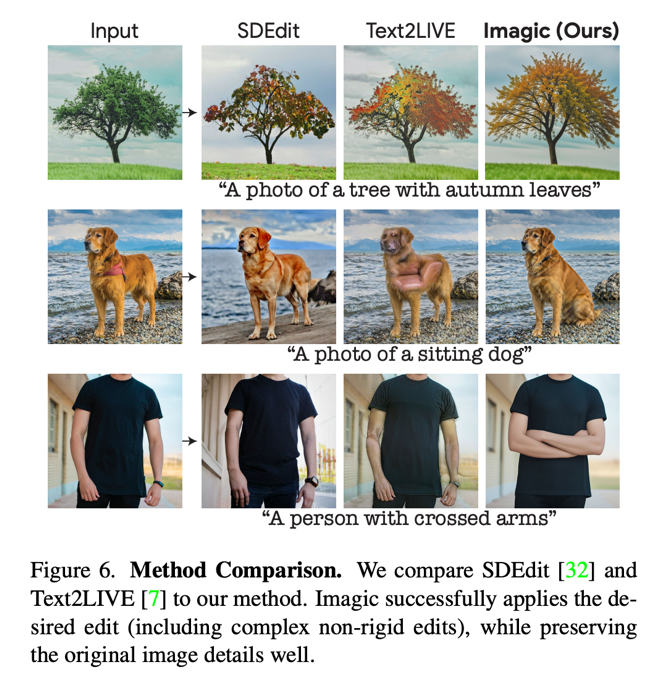
A group of researchers from Google, Technion, and the Weizmann Institute of Science proposed Imagic, a semantic image-altering technique based on Imagen that addresses all the aforementioned issues. Their approach can carry out complex non-rigid changes on actual high-resolution photographs with just an input image to be changed and a single text prompt indicating the target edit. The output images are well-aligned with the target text and maintain the background, composition, and general structure of the source image. Imagic is capable of many alterations, including style adjustments, color changes, and object additions, in addition to more complicated changes. Some examples are shown in the figure below.

Method
Given an input image and a target text prompt which describes the edits to be applied, the objective of Imagic is to modify the image in a way that satisfies the given text while maintaining the most amount of detail.
To put it more precisely, the method entails three steps, shown also in the figure below:
- Optimizing the text embedding. An initial text encoder is used to produce the target text embedding etgt from the target text. Then, the generative diffusion model is frozen, and the target text embedding is optimized for some steps, obtaining eopt. After this process, the input image and eopt match as nearly as feasible.
- Fine-tuning the diffusion models. When subjected to the generative diffusion process, the produced optimal embedding eopt may not always result in the input picture exactly. To close this gap, the model parameters are also adjusted in the second stage while freezing the optimal embedding eopt.
- Linearly interpolating between the optimized embedding eopt and the target text embedding etgt using the model fine-tuned in step B, to find a point that achieves both image fidelity and target text alignment. The generative diffusion model is employed to apply the desired edit by moving in the direction of the target text embedding, as it was trained to completely reconstruct the input image at the optimized embedding. This third stage, to put it more precisely, is a straightforward linear interpolation between the two embeddings.

Results
The authors performed a comparison between Imagic and state-of-the-art models, showing the evident superiority of their approach.
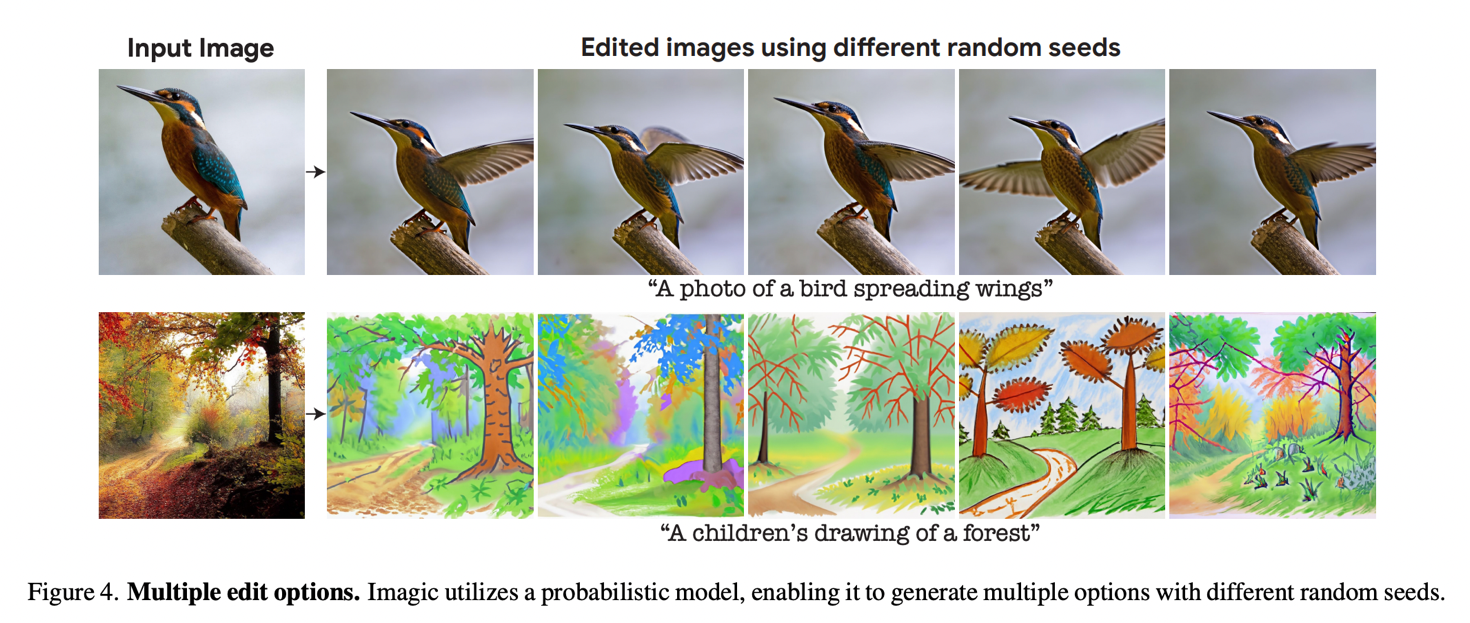
Also, the ability of the model to produce different outputs with different seeds starting from the same input image and text prompt is shown below.
Imagic still presents some drawbacks: in some cases, the desired edit is applied softly; in other cases, it is applied effectively, but it affects extrinsic image details. Nevertheless, this is the first time that a diffusion model is able to edit images from a text prompt with such precision, and we can wait to see what will come next.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Imagic: Text-Based Real Image Editing with Diffusion Models'. All Credit For This Research Goes To Researchers on This Project. Check out the paper.
Please Don't Forget To Join Our ML Subreddit
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
[ad_2]
Source link
