[ad_1]
![]() [SPONSORED CONTENT] In the automotive industry, first movers have a big advantage. Industry success is centered on vehicle research and development, with design, performance and crash safety multiphysics software at its core. Producing high-fidelity simulations, these applications accelerate vehicle time-to-market, allowing engineers to sample more design options and perform more virtual tests in less time. .
[SPONSORED CONTENT] In the automotive industry, first movers have a big advantage. Industry success is centered on vehicle research and development, with design, performance and crash safety multiphysics software at its core. Producing high-fidelity simulations, these applications accelerate vehicle time-to-market, allowing engineers to sample more design options and perform more virtual tests in less time. .
However, these remarkable simulations are computationally and data intensive, leveraging high-performance computing and advanced AI technology resources. In an industry that rewards first movers, a major challenge is avoiding being a slow mover when it comes to technology. The life cycle of on-premises hardware typically lasts 3-5 years. This is a problem in the automotive industry where technology ages like dogs. According to Microsoft, a strategy to ensure design engineers have access to the latest and greatest technology is to move their workloads to the Azure high-performance cloud. This permanently updates the platform with advanced HPC-class hardware and software.
We recently spoke with Rick Knoechel, Senior Solutions Architect, Public Cloud, and Sean Kerr, Senior Manager, Cloud Solutions Marketing at AMD. In recent years, Azure has been the first public cloud to adopt AMD chips, including the latest AMD EPYC CPUs and AMD Radeon Instinct GPUs.
According to Knoechel, automotive engineers work under chronic pressure called a “constrained environment.” Often, not enough computing resources are available to run engineering workloads. And it makes sense, given that automotive design software has evolved to include multiple applications within a single application package, such as multiphysics simulations that combine mechanical, aerodynamics, and thermal cooling. That’s it.
Constrained environments are having a major impact on the end-user community. “These people are the men and women whose job it is to validate the ‘impact resistance’ of new cars,” he said Knoechel. “Suppose we have a new EV pickup truck with a 2000 lb battery. This sort of thing means demand for computing is at an all-time high in the industry.”
According to Knoechel, demand for HPC is not only high, but also volatile.

AMD’s Rick Noochel
“Historically, demand has been very ‘peaked’,” says Knoechel. How many resources do you keep available? When you have “overcapacity,” it’s underutilized and you’re wasting time, energy, and money. And if you’re “undercapacity,” you can’t meet end-user demand. And now, with the high demand for HPC, nearly every on-premises HPC environment in the world is running out of capacity. ”
He shared a customer case study of an auto parts supplier with an on-premises infrastructure of 1,200 cores. This infrastructure slowly eroded productivity due to test bottlenecks that forced design engineers to wait in queues for computation time.
“They had established a best practice of building a physical prototype for FMVSS certification before running final validation tests. There was a rule that you weren’t allowed to create a , so essentially the entire product design and development pipeline had to run through 200 simulation engineers around the world, waiting in queues We were creating a $6 million to $7 million annual bottleneck in terms of staff time.”
Fast forward. The company’s engineers are now working in Azure, where Knoechel says annual cloud spending is only about $1 million, running four times as many crash simulations and four times as many software licenses as his. Additionally, Azure’s high availability and scalability (“elasticity”) provide computing resources regardless of daily changes in HPC demand. As a result, Knoechel says: “Productivity has been unlocked.”
Knoechel pointed to other problems for automotive companies with on-premises resources. One is to staff the data center he manager with expertise in operating HPC class infrastructure. Hiring and retaining them is not easy. Its expertise is commonly found in large automotive OEMs, but it has become a big issue among auto parts manufacturers.
“More and more design work is being pushed to suppliers,” says Knoechel. “They have to be more innovative, they are under pressure to deliver better and lighter products, and time to market is a big challenge.” As a result, cars with as many as 5,000 cores Suppliers are now moving their infrastructure to the cloud.
Another issue for on-premises organizations is that disruptions in the technology industry supply chain are delaying the delivery of advanced servers with the latest components (latest chips, power supplies, storage and memory drives). But Azure is one of the largest server OEM customers, so it’s at the forefront of new server offerings.
“Azure adopts the latest technology very quickly,” says Kerr. “For example, they were the first to adopt 3 of us in the cloud.rd Gen ‘Milan’ EPYC with AMD 3D-V Cache, they covered our product very well when it came out. It may be renewed every 5 years and requires big bets by the planning team. But since Azure is constantly being updated, customers don’t have to make that big of a bet. ”
Additionally, Azure’s HPC team has created an on-premises-like product that reflects the nuances of users’ high-performance computing needs. Not only does Azure incorporate new advanced technologies and storage and deployment tools used in HPC, but it also has a lightweight hypervisor that delivers bare-metal-like performance, all supported by Azure’s HPC technical staff. It is also the first major cloud provider to offer a fully integrated Infiniband fabric.
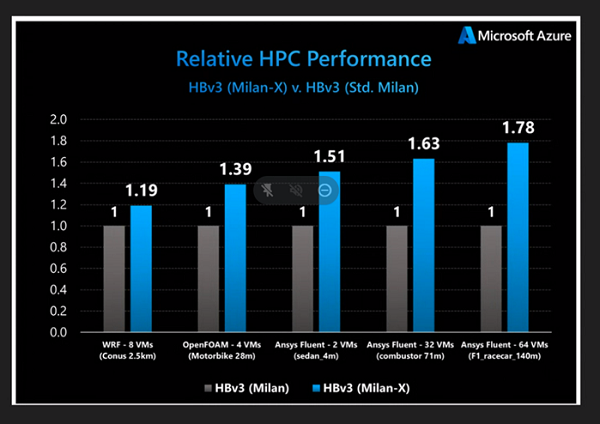
Last March, Microsoft announced an upgrade to Azure HBv3 virtual machines powered by EPYC 3rd generation chips. Microsoft’s internal tests show that the new HBv3 series delivers up to 80% better performance in CFD, 60% better EDA RTL (right-to-left), 50% better in explicit finite element analysis, and 19% better in weather simulations. is shown. Much of that improvement comes from the new EPYC processor’s 3D-V cache. In practice, the ~80% improvement in run time on the 140 million cell ANSYS Fluent CFD model means he can run two jobs for the time it took to run one job. increase.
Kerr and Knoechel add that automotive OEM customers have seen similar performance improvements running full-vehicle Ansys LS Dyna crash simulations with over 20 to 30 million elements. I was. These runs used to run him for 30 hours, now they take him 10 hours.
“If you’re in charge of safety for a major global vehicle, you should pay attention to that,” says Knoechel.
[ad_2]
Source link
